虽然前面自己写过一个 Python Logging 的各种玩法(折腾 Python logging 的一些记录),结果没两个月,自己就在之前特意叮嘱过的地方翻了车
事情是这样的,我们的项目使用 Flask 作为业务框架,用 Celery 作为异步任务框架,按上篇里提到的,我们加了个 Filter 来加入 request_id 用于跟踪同一个 Web 请求或同一个 Task。所以,我们的 logging.conf 一开始是这样的,在 logfile 这个 Handler 里加入 request_id 并打印到日志文件,我们用阿里云的 logtail 把所有部署实例的日志文件都收集到一起,这一层 app Logger 往上抛是让终端都打印所有的日志,并且用 sentry 这个 Handler 在最上面收集各种异常报错
logging_conf = {
"version": 1,
"disable_existing_loggers": True,
"filters": {
"addRequestId": {
"()": "app.utils.logging.request_filter.ContextFilter"
}
},
"formatters": {
"standard": {
"format": "[%(asctime)s][%(levelname)s][%(pathname)s:%(lineno)s][%(funcName)s]: %(message)s"
},
"withRequestId": {
"format": "[%(asctime)s][%(levelname)s][%(relpath)s:%(lineno)s][%(funcName)s][%(request_id)s]: %(message)s"
}
},
"handlers": {
"console": {
"level": "DEBUG",
"class": "logging.StreamHandler",
"formatter": "standard"
},
"logfile": {
"level": "DEBUG",
"class": "logging.handlers.WatchedFileHandler",
"filters": ["addRequestId"],
"formatter": "withRequestId",
"filename": "log/app.log"
},
"sentry": {
"level": "ERROR",
"class": "raven.handlers.logging.SentryHandler",
"dsn": "DSN_URI",
"string_max_length": 512000
}
},
"loggers": {
"app": {
"level": "DEBUG",
"handlers": ["logfile"],
"propagate": True
}
},
"root": {
"level": "DEBUG",
"handlers": ["console", "sentry"]
}
}
后来,为了把 Celery 调度信息等也通过 logtail 收集到阿里云,我们就把 logtail 的源从日志文件改成了 stdout/stderr 输出,不同时收集日志文件是因为同样的日志在 logfile 和 console 里会出现两次,没有必要。但是只改 stdout/stderr 又会导致收集到的信息没有我们辛苦加进去的 relpath 和 request_id,一个很直接的思路就是,在 app 这层 Logger 上加一个 consoleWithId 的 StreamHandler,并且 formatter 用 withRequestId 不就好了,然后限制 app Logger 的 propagate 为 False 禁止上抛,问题应该完美解决?等会,这里有好几个问题
第一个问题是,如果 app Logger 不往上抛,那万一异常了,sentry Handler 也收集不到错误?头疼医头脚疼医脚,那就给 app Logger 也挂上 sentry Handler 不就解决问题
第二个问题是,handlers 的处理顺序是不是严格按我们配置的顺序来?如果不是的话,consoleWithId 进入的时候,可能 addRequestId 这个 Filter 还没执行,出现了输出时拿不到 relpath 和 request_id 那不就挂了?这个简单,把 Filter 移到 Logger 这一层不就解决了。至此,配置如下(只摘录改动部分)
# ...
"handlers": {
# ...
"logfile": {
"level": "DEBUG",
"class": "logging.handlers.WatchedFileHandler",
"formatter": "withRequestId",
"filename": "log/app.log"
},
"consoleWithId": {
"level": "DEBUG",
"class": "logging.StreamHandler",
"formatter": "withRequestId"
},
# ...
},
"loggers": {
"app": {
"level": "DEBUG",
"filters": ["addRequestId"],
"handlers": ["logfile", "consoleWithId", "sentry"],
"propagate": False
}
},
# ...
翻车就翻在「这个简单」上,按这个思路配置后,跑起来还是在 consoleWithId 的 Handler 上输出报错,而且报的就是 relpath 和 request_id 字段不存在。怀疑自己的配置有问题,跑到代码里打日志的地方用 logging.getLogger(__name__) 看拿到的到底是哪个 Logger,以及上面挂了哪些 Handler,还有 Logger 和 Handler 的 Filters 都配的啥,发现除了 app 根上,如果是 app.foo 这样的路径,拿到的都是一个叫 celery.utils.log.ProcessAwareLogger 的 Logger,而且没有任何 Handler 和 Filter 挂在上面,所以,Celery 你这个坏人,到底对我的代码做了什么?
跑去翻 celery.utils.log.ProcessAwareLogger 这个东西的源码都没看出个所以然,似乎只是为了保证 Flask 的 signal handler 机制正常,排查思路也断掉,再跑去看看我们那个 app.utils.logging.request_filter 的处理,有没有哪里不对的,在这个自定义的 filter 里裸用 print 打印,发现这个 filter 压根没被调用到?嗯?没被调用到?
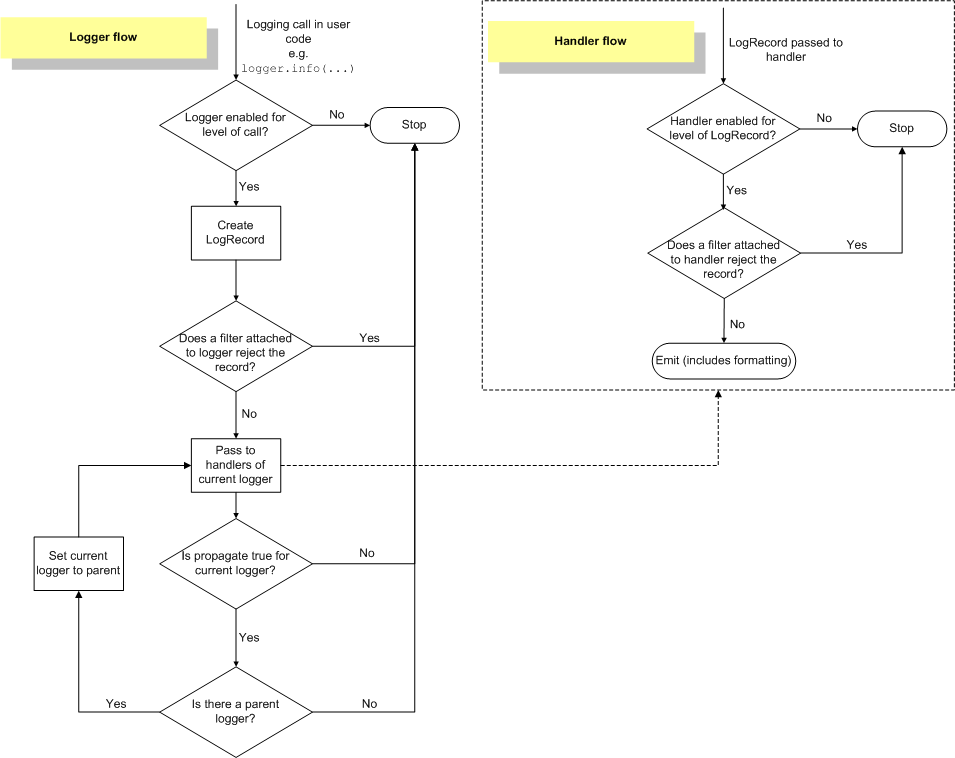
回去看自己的上一篇,果然里面自己就提到过这里有坑(主流程解释的第 5 步)
如果开启了日志往上传递,则判断当前 Logger 是否有父 Logger,如果有的话,直接将当前 LogRecord 传给父 Logger 从 4 开始处理(跳过 1/2/3,注意此处级别控制 1 会不生效,绑定在父 Logger 上的 Filter 也不执行)
WTF!果然坑都是自己不掉一遍,别人说千万遍也不会记得的,哪怕说的这个人是自己。那好咯,把 addRequestId 这个 Filter 还是从 app Logger 上移到 Handler 层面上好了,每个需要的 Handler 都给挂上,多点性能开销就多点吧
不过这样配的感觉还是怪怪的,比如有些错误会被 sentry 收集两次,因为在 app 里一直往上抛会被 app Logger 里的 sentry 收集,如果这个错误还继续往上抛到了框架层面,框架的错误还会被 rootLogger 的 sentry 又收集一次。而且,既然 app 的里面和外面都有终端和 sentry,为啥不在最外面一次处理好,中间拦着不往上抛没有任何意义。调整了下,直接把 standard 这个 Formatter 和 console 这个 Handler 给去掉,在 rootLogger 上挂 consoleWithId 和 sentry 就好,最后完整的配置如下
logging_conf = {
"version": 1,
"disable_existing_loggers": True,
"filters": {
"addRequestId": {
"()": "app.utils.logging.request_filter.ContextFilter"
}
},
"formatters": {
"request": {
"format": "[%(asctime)s][%(levelname)s][%(relpath)s:%(lineno)s][%(funcName)s][%(request_id)s]: %(message)s"
}
},
"handlers": {
"logfile": {
"level": "DEBUG",
"class": "logging.handlers.WatchedFileHandler",
"filters": ["addRequestId"],
"formatter": "request",
"filename": "log/app.log"
},
"consoleWithId": {
"level": "DEBUG",
"class": "logging.StreamHandler",
"filters": ["addRequestId"],
"formatter": "request"
},
"sentry": {
"level": "ERROR",
"class": "raven.handlers.logging.SentryHandler",
"dsn": "DSN_URI",
"string_max_length": 512000
}
},
"loggers": {
"app": {
"level": "DEBUG",
"handlers": ["logfile"],
}
},
"root": {
"level": "DEBUG",
"handlers": ["consoleWithId", "sentry"]
}
}
因为 Logger 的 propagate 默认就是 True,所以相对于第一版在 app 这个 Logger 上去掉了这条配置也没关系
最后,因为 addRequestId 这个 Filter 还是会被调两次,想优化下性能,就在 Filter 做完后加一个标记,下次再进来如果看到有这个标记就直接跳过,以及,对于非项目内的日志就不要用项目内的相对路径而用绝对路径替代。代码如下
# coding: utf8
import logging
import os.path
from celery import current_task
from flask import g, has_app_context, has_request_context
_proj_root_path = os.path.abspath(os.path.join(__file__, './../../../../'))
_proj_root_length = len(_proj_root_path)
class ContextFilter(logging.Filter):
def filter(self, record):
# ignore duplicate filter
if hasattr(record, 'filter_by_yewen'):
return True
# request_id for flask web or celery task
request_id = 'Standalone'
if has_app_context():
if has_request_context():
request_id = g.get('request_id', 'UnknownRequest')
elif current_task:
request_id = current_task.request.id or 'UnknownTask'
record.request_id = request_id
# handle log_decorator pass
record.funcName = getattr(record, 'orig_funcName', record.funcName)
record.pathname = getattr(record, 'orig_pathname', record.pathname)
record.lineno = getattr(record, 'orig_lineno', record.lineno)
# relative path
if record.pathname.startswith(_proj_root_path):
record.relpath = record.pathname[_proj_root_length:]
else:
record.relpath = record.pathname
record.filter_by_yewen = True
return True