2007.07.18 百度 北京中关村普天大厦 第一份实习
2025.07.18 美登 杭州城西银泰城 工作 在美登的第十二年
彻底漏了一篇,有一次算没有的,和之前三年一间隔的记录

MacBook Pro 16 M3Max and ThinkPad X1 Carbon 2024
人生得意须尽欢,该省省该花花,赚钱了也花钱让自己开心下,不要总扯性价比智商税,情绪价值也是价值
MacBook Pro 16, M3Max 16cpu 40gpu, 64G RAM, 1T SSD
ThinkPad X1 Carbon 2024, U5-125H, 32G RAM, 512G SSD, 2.8K120Hz OLED, LTE
如题,莫莫同学左手小臂骨折了,用更准确的说法,桡骨尺骨远端骨折,就是左手手腕往手肘方向去一点的骨头断了
据莫莫自述是当天吃过午饭后,午休时跟同学们一起在操场上玩单杆,他荡下来时看地上有一块垫子,想落到垫子上,但自己下落方向并不在垫子那边,落地时没落稳,手撑了一下,后面太疼叫同学送去学校医务室,校医看过说手都扭曲了,估计是骨折了,联系班主任叫家长赶紧带去医院
我那天本来答应了奥奥下午去参加奥奥幼儿园班上的家长开放日,刚吃完饭快一点钟准备回去,接到莫莫班主任打来的电话。第一反应是不太好,因为老师平时有事情都是钉钉上说,最多打个钉钉语音,老师说莫莫在学校摔了,需要家长带去医院看一下。前面我还没意识到问题的严重性,哪怕看校医拍的照片说手上用了冰敷加夹板,以为只是扭伤的程度,因为校医说他还挺坚强的都没有哭
赶忙开车到学校,直接打双跳停学校门口,拿钉钉上班主任的消息问保安医务室在哪边,径直去到医务室,我还想是不是社区医院就可以拍片搞定的,校医说建议去大一点的医院,讨论了下附近同德的口碑一直不太好,要么去浙一余杭。去浙一路上看时间莫莫妈在单位应该午休结束,还是应该先说一下,结果喵说为啥去浙一不直接去省儿保,浙一可能弄不了的,我说我都在路上了,校医说应该也可以的
到浙一余杭,停车找半天,去急诊,还要先分诊才给挂号,跟分诊台确认这里能不能看,不行的话我就直接去省儿保了,得到分诊台可以的答复后挂号等,那边喵赶紧请了假往这边过来。急诊医生看说小臂都变形了,里面骨头估计是骨折了,他们这边没有十二岁以下儿童的夹具,不一定弄得了,不过去拍片先。拍片回来等医生电脑上能看到片子,小臂两根骨头桡骨和尺骨都断了,本来 180 度直线过去的变 150 度左右的断掉折弯。这时候紧张炸了,娃太坚强也不见得都是好事,之前看他没哭没咋的,真没意识到有这么严重
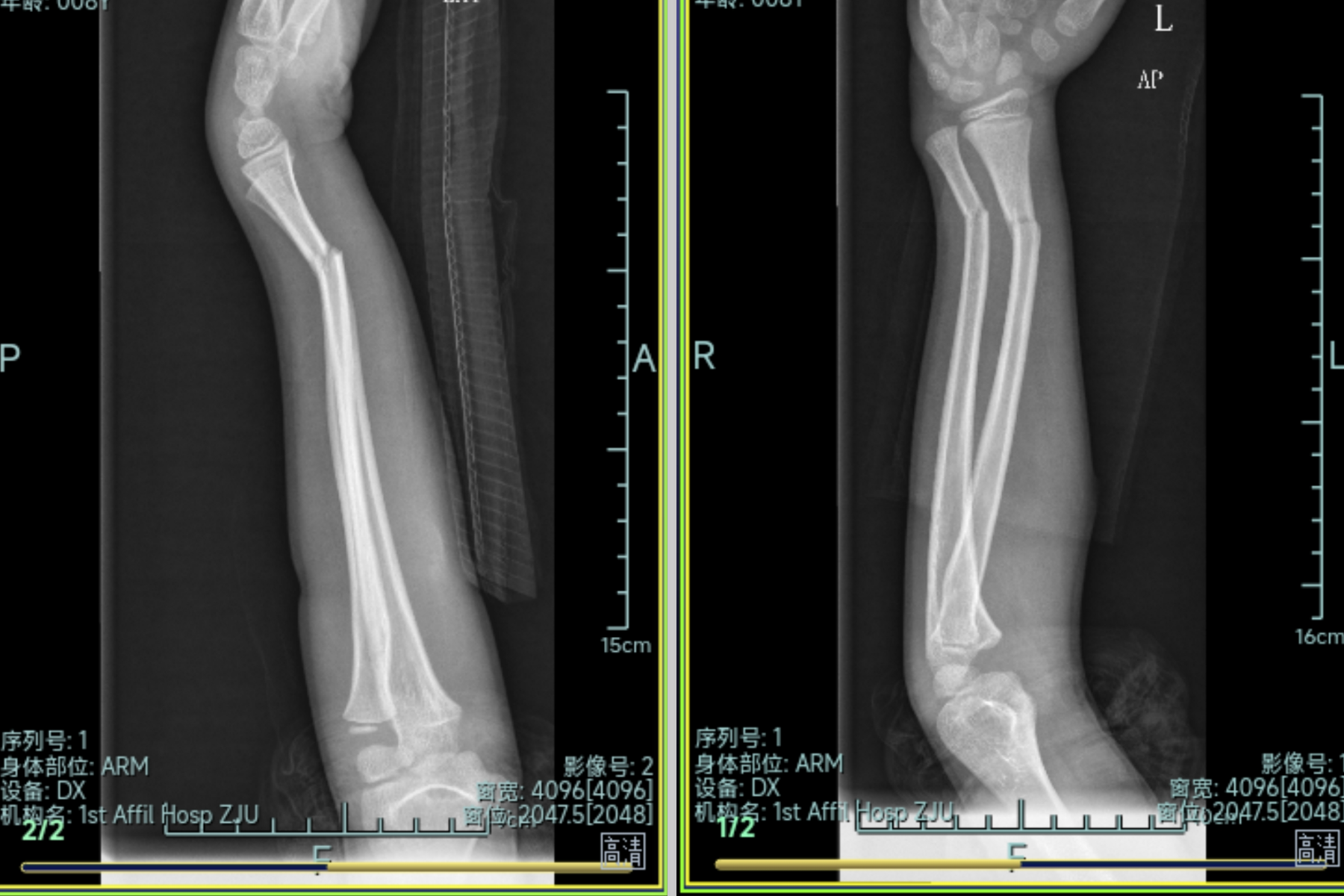
骨折X片
浙一的急诊医生说他们这弄不了,让把电脑上的片子用手机拍照(因为医院的小程序里还不能自己查看到),直接去省儿保滨江吧。那边喵快到浙一余杭附近的地铁站,约好直接去地铁出口带上她往滨江去。到省儿保已经下午三点多,医院地下车库有空位,停好车一起上到急诊。急诊医生估计是见得多了,看过片子后说建议手工大致复位,然后打石膏固定,不过还是有没法完全康复的风险,需要家长签字确认后实施。解释说这个断法还到不了要手术的程度,而且手术也不能保证完全康复,流程麻烦娃也受罪
都这样了那还能怎么办呢,抱紧莫莫,让医生给拉直复位,到这时候终于是痛得不行了嗷嗷大哭,让人心疼。复位后打石膏,先是铺在棉纱布上像果冻或橡皮泥一样的材料,手拉直后敷上去包裹住,外面用纱布再缠成像木乃伊一样,最后用缠的纱布尽头做了个挂绳挂在脖子上辅助定位,再等石膏发热变硬后再拍片确认固定的情况。石膏跟我印象中的不太一样,最终挂脖子的从缠的纱布出来也出乎意料
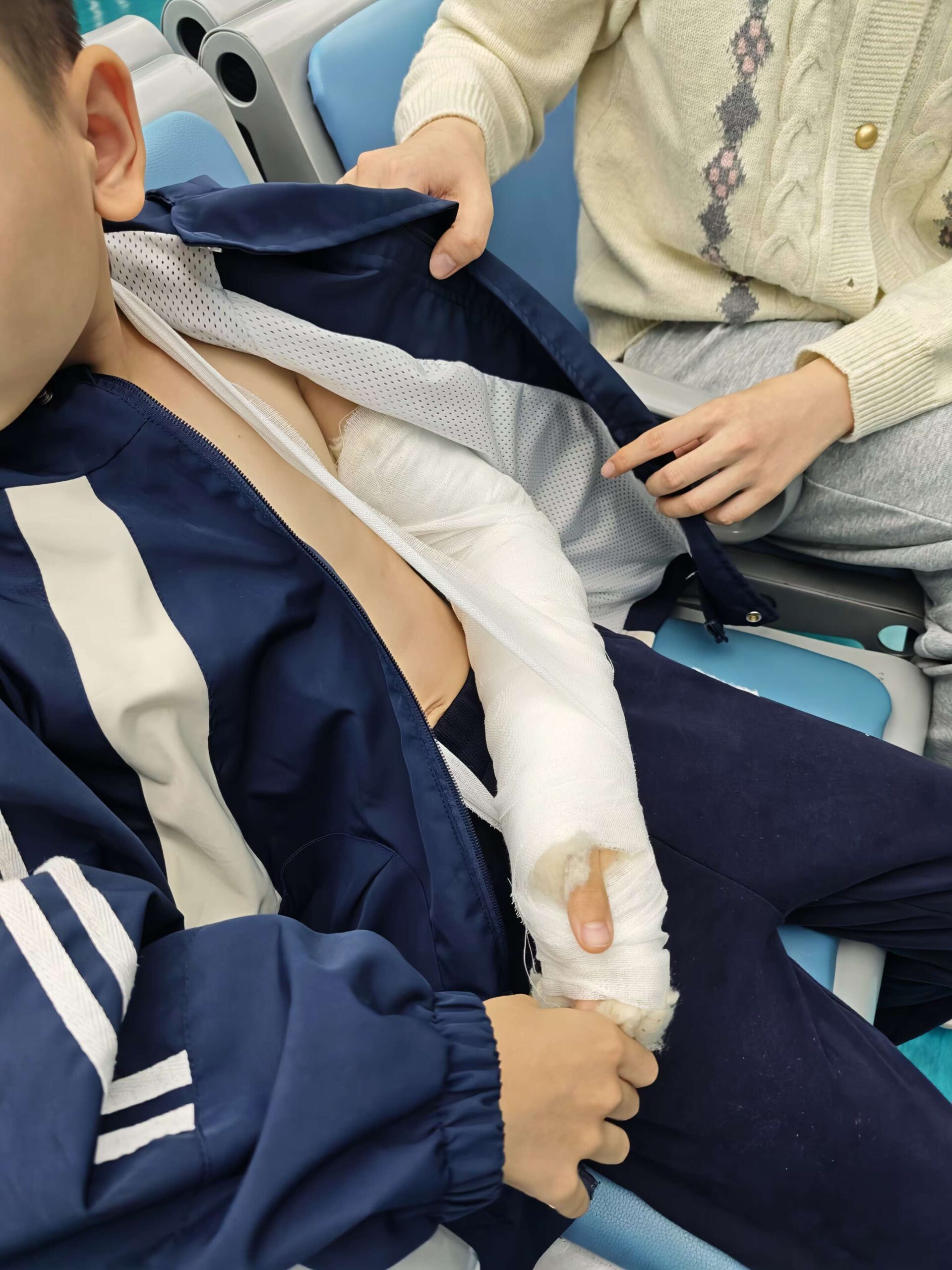
石膏固定
拍片的结果医生说还行,能有八九十分,但外行看起来还是心惊胆战,纵向基本对齐对直,横向一根骨头有一点点错位,另一根骨头断开处还有差不多三分之一的错位,呈「与」字去掉两横一样形状。问是否要吃药或补钙,说都不用,最多按正常剂量保持维生素D摄入,三天后来复查。既然都这样了,那就遵医嘱,谢过医生后准备回家。走之前按莫莫的惯例,必然要吃一顿麦当劳,有过鸡翅薯条什么的再走,原话是「我都来儿童医院了还不吃顿麦当劳那我不是白来了」,娃你也真的心大,让人无语,好好关心下你的手怎么好吧
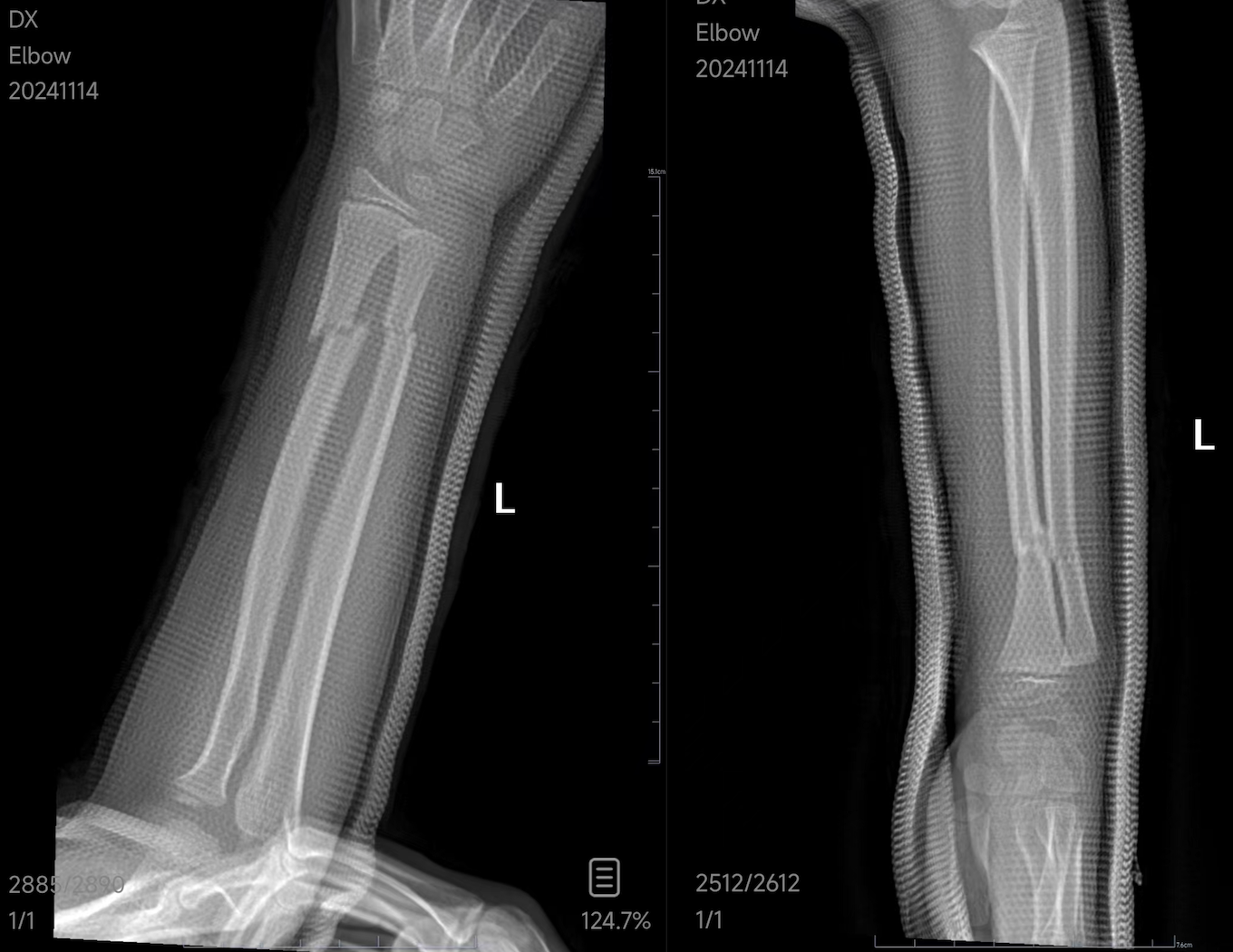
复位打石膏后X片
衣服是不好穿的了,回家用爸妈的T恤,趁袖筒大穿过左手,穿个马甲背心,再外面就只能穿着右手,左边披着。脖子上挂的纱布绳,感觉会勒得慌,找隔汗巾叠一下垫上。睡觉老实跟着睡大床,好帮忙照看下,自己小床别磕到床沿啥的造成二次伤害。上厕所、吃饭、洗漱什么的回到全程照顾的模式,慢慢自己能做一点。上学就别去了,一不好活动自理二怕再磕碰到,衣服都不好穿别叠加冻病了。在家学习等前一两天适应好能左手打着石膏贴近桌子后也还好,写字什么的左手压不住就潦草就潦草吧。在网上看到有袖子能魔术贴包起来的,赶紧下单给准备上,到了后和预期的差不多,石膏外面能有一层衣服,往外的马甲就临时托着打着石膏的手穿一下,再往外就只穿右手,左手披着了
后面就是按期复查,没有更好,也没有明显变差。按医生和喵咨询同学朋友的说法,骨头对上一半以上就还行的,后面慢慢恢复吧。我们问那种挂脖子上的辅助带是否有需要,医生说你们石膏都没拆想那么多干嘛,估计也要一个半月后再说
在公司连的内网无线网络是通过 WPA/WPA2 加 Radius 走 LDAP 认证的,最近有一个奇怪的现象在多台 Win11 宿主机上出现,明明网络是连接状态,但从别的机器发起远程连接,接通的瞬间宿主机切到登录界面时网络就掉了
宿主机连有线没有这个问题,连 WPA2-PSK/WPA3-SAE 模式只用 WiFi 密码连接的无线网没问题
网上各种找解决办法,包括但不限于 设置网卡的电源配置以免节能模式关闭了网卡、升级补丁和驱动、导出网络配置文件并应用到所有用户 等,因为都没起作用所以也不在这里给引用链接了
最终的解决办法是「从已知网络里忘记这个接入点,重新添加一次」就好了,就是这么无厘头……
在 Win11 里忘记已知网络的设置入口在 设置 – 网络和 Internet – WLAN – 管理已知网络
莫莫戒尿不湿戒得挺早,印象里两岁夏天开始白天戒掉,然后慢慢晚上也不用的
奥奥戒尿不湿就慢很多,白天是两岁半后,快上托班才戒掉的,晚上则是到三岁半的冬天才没有穿
发现奥奥晚上睡觉穿拉拉裤也不会尿尿后,大家一致决定晚上就穿小内裤睡觉,这样小朋友还是要舒服很多,风险则是可能会尿床
一般来说,如果晚上睡前半小时一小时没有大量喝水或喝牛奶,睡前拉好臭撒过尿,大概率是不会尿床的。大概一两个月可能会有那么一次,因为晚上喝奶什么的,睡前又没好好上厕所,快到早上起床时尿床啦,晚上带睡帮盖被子或调整下睡姿时会摸到,然后赶紧换掉衣服裤子,再看如果还早就挪到床的另一头继续睡,不早了那换衣服时可能就被弄清醒了,那就起床吧
前几天有一晚,早上六点多带睡的爸爸醒来看奥奥没盖被子,给他盖起来,过一会奥奥把被子卷走裹着,等爸爸再眯一会七点准备起来时,一摸怎么屁屁那有点湿,不至于这么快就出汗吧,一看哎呀尿床了,赶紧换和把弄湿的被子先洗掉,等起床后再弄床单床垫啥的
第二天早上,还是六点多爸爸帮盖了下被子,再过没半小时又摸到身下有湿的,怎么会连着两天尿床啊,尴尬
回想了下可能是晚上贪吃,吃了两小块西瓜,然后睡前撒尿没撒多少,后面在床上睡前故事环节后没有再去一次,而前一天晚上可能是踢被子睡在空调房里,有点凉飕飕,然后被子一裹,暖和了加睡一晚上本来就有憋尿,下意识就没控制住
因为连续两晚都有尿床,把奶奶都搞害怕了,虽然是夏天的大晴天,也架不住天天要洗洗晒晒。看之前剩的拉拉裤还在,奶奶在第三天睡前就给换了个拉拉裤,睡到十二点多整个人比较燥,翻来覆去哼哼唧唧半天,爸爸抱起来去撒个尿,看空调可能有点闷就再调低一点,并设了个定时再改高,回来才安心睡好
再后面两晚,到早上六点爸爸醒一下,就干脆抱着睡得贼香的奥奥去撒个尿回来继续睡,被折腾一番总还是会哼唧的娃,要再贴着爸爸或抱着爸爸才能安心睡着,小朋友这会软糯香滑,还是超可爱超幸福,是人类繁衍本能的精神奖励吧
在 Chrome 系浏览器上,包括 Chrome、Edge、Arc 等,SwitchyOmega 作为开发测试和科学上网的必备工具,一直是新机优先装的插件,或等待插件自动同步赶紧配好
不过由于 SwitchyOmega 的开发者已经不再维护 [1][2],Chrome 对插件的 manifest meta 要求从 v2 到 v3,再加上原版的 SwitchyOmega 在 Arc 的弹层总有些问题,所以最近一直在找替代方案
在 SwitchyOmega 作者建议有维护能力的人去 fork 一个 v3 版本的推文后,发现了 ZeroOmega [3],看了下项目代码就是直接 fork 然后改各种兼容配置项,界面和文档里好多地方还是 SwitchyOmega,一开始还不太好用,不过这两天用下来已经可以平替了,除了插件 Logo 相比之前略有不协调,但在浏览器插件栏显示的还是之前的圆环,完美替代
安装地址:Chrome Web Store、Microsoft Edge Addons
注:
[1] SwitchyOmega 的项目地址 https://github.com/FelisCatus/SwitchyOmega
[2] SwitchyOmega 不再维护的推文 https://x.com/_catus/status/1759413399270936672
[3] ZeroOmega 的项目地址 https://github.com/suziwen/ZeroOmega
收了一台 X1 Carbon 2018,配置是 i7-8650U / 16G / 512G / 2K / FPR / 4G LTE,重装系统后发现偶尔会出现屏幕卡死的情况,具体表现是屏幕上任何东西都不动,鼠标光标无法移动,但按大小写锁定等按键,键盘上的灯是在正常响应的,说明系统没卡死。做了如下排查尝试
最后搜到 https://club.lenovo.com.cn/forum.php?mod=redirect&goto=findpost&ptid=5559793&pid=65060757 这个帖,在 Intel 显卡控制中心里把面板自适应刷新的开关关掉就好了,具体路径在 系统 – 功率 – 使用电池/使用外接电源 下的 面板自刷新
这个奇葩的问题只出现在屏幕型号为 LEN40AA 的 2K 屏的版本上,普通的 1080p 和 4K 屏都没有这个问题,难怪没搜到太普遍的解决办法。之前我的排查思路有遗漏,是因为大部分我插电的时间都连了外接显示器,在外接显示器上这个 bug 触发不出来,而有时候我又是没外接屏幕插电用,所以没有找到稳定复现的条件
上次给奥奥的记录都是半年多前了。这半年,从托班毕业,进入幼儿园,外公外婆换爷爷奶奶在我们身边帮带娃,伯母离开没再带奥奥
去幼儿园适应还行,有过托班经历,在规则感方面衔接是好一些。吃饭还是困难户,不愿意自己吃,好在幼儿园几个老师都挺负责的,不帮忙上手循循善诱带上道。此处特意插一句,班主任老师家自己的娃在上中班,刚好有更相近的体验,对小朋友们还是有更贴切的感触。会因为不好意思而去美化自己,老师问在家是不是自己吃的呀,答是的,问伯母没喂奶奶没喂,答嗯嗯。午睡么马马虎虎,跟哥哥一样只有在幼儿园才肯午睡,不像托班老师会有更细致的反馈,也不知道他睡成啥样,但从晚上回来总嗨到十一点才睡着应该是睡好了的。前面戒尿不湿没太戒掉,现在晚上睡觉还是穿拉拉裤,在学校有时候玩嗨了忘了找老师帮忙,就会尿裤子下午放学带回大礼包。早上入园其实是适应了的,但还是习惯性黏乎乎进去前要抱一下,特别是伯母走了后早上爸爸送,跟爸爸腻乎得更加夸张。下午放学总要在路上经过便利店去买点零食,不然就各种不要回家,明明家里也有各种零食啊,带去了都不认
伯母带奥奥到十一月底,后面就去市场上做别家了,刚分开时奥奥的情绪脾气都挺差,也只有爸爸哄得住,一个后果就是之前本来跟爸爸就嗲嗲的腻乎劲,现在夸张到不忍直视。会动不动就说我要离家出走了,我不要在这个家了,天气冷了往外跑也冻病过一次
吃喝拉撒睡等生活方面。在家吃喝就总要喂,还动不动就点名「我只要爸爸喂的」。撒尿基本可控,但如果闹情绪发脾气了会用主动尿裤子来对抗,这都什么奇怪的思路,之前莫莫小的时候倒是有过实在闹腾被摁住揍的时候尿裤子。拉臭么有一阵子总是晚上刚睡着来一泡或早上快起床前来一泡到拉拉裤上,一开始没经验以为就是尿尿了,一扯拉拉裤还把床弄脏,后面习惯了他这个奇怪的节奏,就总是睡着被抱起来洗屁股,最近倒是认同坐在小马桶上拉,而且都是睡前固定时间去「试试吧」。睡觉跟哥哥半斤八两,在家不午睡,除非是出去玩累了下午在回来车上睡,但一放床上有点风吹草动就醒了,晚上洗漱好熄灯到床上还能再各种说话玩嗨到差不多十一点,睡着后稍微盖多点就肩膀出汗,跟哥哥一样一样,踢被子的姿势是平躺双脚缩到胸前整个往脚那边踢掉,然后睡到被子上,反正么盖薄了家长总担心会冻着,盖厚点就半夜没事给看看吧
在家总想去玩常规尺寸的乐高,更多可能就是觉得要跟哥哥一样,但哥哥做的作品又不让他动,常规尺寸么现在年纪好像又不太够,按他平时看的玩具视频买了一套兼容乐高德宝尺寸的恐龙滚球,果然又被哥哥过来各种蹭,年末时再买了一套乐高德宝的套件,凑一起现在手部精细动作还不错,另外买的一大包乐高常规尺寸的创意包,就还是被哥哥连哄带骗给骗走了。看书不太有耐心,基本没有能好好看完的,都是快速翻,前阵子要买了一套怪物的书,最近是顺着那个怪物书又要买一套发现恐龙系列,这套书十几年前的了现在能找到的都是溢价快十倍的二手,在拼多多买了几本,有一本是真的原版,三本盗版自己彩打的勉强还能看,另外有两本就是挂羊头卖狗肉发的别的书,直接仅退款处理了,发现恐龙这一套书里最爱的是《翼龙和海龙》和《史前哺乳动物》,已经能把所有的名字记下来,一翻就能说出这是啥
跟哥哥每天打打闹闹家里吵翻天,打不过哥哥么又总要凑上去,偶尔耍赖乱扔东西又会被哥哥吐槽「凭什么奥奥可以怎样怎样而不挨揍」。俩娃就是啥都得双份,不然就是「我也要」「不公平」,哪怕最后到手了就嫌弃,吃不吃玩不玩是我的事,要不要有没有那这个一定要保证端平
哥哥抢了我的鸡块
某次带了份麦当劳回去,本来哥哥喜欢吃鸡翅弟弟喜欢吃鸡块,相安无事的,结果鸡块被哥哥连哄带骗吃掉了大多数,然后弟弟就这样念叨了几个月,特别是觉得委屈要跟哥哥拉平,或自己得了便宜又不想哥哥也有时就会把这个事翻出来
我不要外婆了,我不要妈妈了,我不要爸爸……去上班了,我要爸爸在家陪我
伯母走了后跟家里人闹脾气,其他人都是「我不要谁谁了」,到爸爸这估计实在是再没有替代的了,就硬生生在「我不要爸爸」这里停下,然后接「我不要爸爸去上班了」,带娃带到头大想逃避下家庭责任的爸爸连借口都找不到
我已经迫不及待啦
不确定是从哪个动画片或哪里学会的,最近会开始用各种听上去更高阶的词语,比如这个「迫不及待」,就是最近出场率很高的一个
那好吧
会撒娇会耍赖会黏着爸爸各种不放,但如果真的发现爸爸是坚定的说要去上班或要怎样,大多最后还是会讲道理的,偶尔委屈偶尔释然大度的来一句「那好吧」,其实也能自己玩。可能对爸爸格外嗲也是因为爸爸平时舍不得冷落或凶他,更宠更亲密一点,怎么说呢,爸爸还是希望小朋友对家长有足够的信任和安全感,怎么控制好度,不要腻乎过头就好
公司有一批旧 i5-7200u 的笔记本电脑,打算装 Win11Pro 提供远程访问,做一些测试用,发现直接切换专业版序列号提示错误,准备把系统默认的系统通过 ISO 文件先升级到 Win11 23H2 的 Pro 版也提示处理器不支持
通过新增注册表项解决此问题,在 Computer\HKEY_LOCAL_MACHINE\SYSTEM\Setup\MoSetup 路径下,新增一个 DWORD (32-bit) 字段,命名为 AllowUpgradesWithUnsupportedTPMOrCPU 并将值设为 1,再运行 ISO 里的 setup.exe 就不报错了
从早期真正放在笔记本底部的 Dock 时代开始,就对 ThinkPad Dock 这样底座连各种线缆,笔记本电脑本体随时拔了就走的模式特别喜欢,买过用过 T60、X200、X230 的底座式扩展坞,和 40A9、40AC 两个外接式的扩展坞,本文介绍下 40AC 这个雷电三协议的扩展坞
办公室桌上这个已经用了两年多了,之前在 v2ex 上开了个帖介绍记录:买了个 ThinkPad 40AC 雷电 3 扩展坞给 2020 Intel i5 MacBook Pro 13 用,近乎完美体验一线通 ,本文为这个帖的整理更新
因为在办公室,对 MacBook Pro 外接两个 4K 显示器,加上有线键鼠耳机等需求(蓝牙有干扰和延迟),每天笔记本过来插拔一堆线,期待能用上雷电接口连供电加显示数据等特性,一根线搞定
现在桌上还有一个铭凡类似 NUC 的小主机装着 Windows 当主力机在用,也期望能更简单把这一堆外设在小主机和笔记本之间切换
在 2021 年那个时间点,之前能搜到给 MacBook Pro 的扩展坞,要么指向 CalDigit 这种苹果官方背书但贼贵的,要么是 HP 或 Dell 家需要装驱动且存在 macOS 升级后不可用的风险,或者输出接口没法满足(比如最核心的 2x 4K@60Hz)
ThinkPad 的扩展坞,公司之前买过一个 40A9,是比较早的 USB-C 协议扩展坞,能一根 USB-C 上行到笔记本电脑,解决 供电+单个显示器+USB+LAN+耳麦 的需求,但 macOS 接多个显示器时只能被当成同一个输出源输出同样的信号,偶发有笔记本休眠后再唤醒时显示器无法唤醒的问题,需要重新插拔一下(用在 ThinkPad 上可以多个输出也没唤醒问题),同时最大只能双 1080p@60Hz,所以没有继续选这个
当时参考 https://post.smzdm.com/p/aekzgq6k/ 这个文章,对比下来 40AC 应该是满足需求且价格最合适的,事实上在 2021 年八月,闲鱼五百多买了一套 40AC 加 135W 电源加雷电三线,用下来也是近乎完美的
在 2023 年八月这个时间点,可选的除了已经全套价格降到 300 以内的 40AC,还有 40AN 这个二代雷电三扩展坞,和 40B0 这个雷电四扩展坞等,不过后面两个价格还是略贵,所以当家里有需求时,我还是再买了个 40AC
官网在 https://support.lenovo.com/us/en/solutions/acc100356 ,各种驱动固件和技术规格都可以从这里找到
先上个图,左侧那个黑色长条形就是 ThinkPad 40AC 扩展坞本体,后面那个黑色的大块头电源是连这个扩展坞供电同时给更上行设备提供充电能力,右侧那个银白色的小方块是铭凡 NPB5 小主机

目前接上去的线包括
接 MacBook Pro 13(2020 Intel i5 款)和 MacBook Pro 14 (2021 M1Pro 款)都是即插即用,不需要破解,不需要改 SIP 或系统设置,测过从 macOS Catalina (10.15)一直到 Ventura (13.x)都是可用的,在可见的未来也不应该出其他问题
接 ThinkPad X1 Carbon 2018(Intel i5-8350u)、Lenovo Miix 720 (Intel i5-7200u) 、铭凡 NPB5 (Intel i5-13500H) 这些 Windows 设备也都是完美工作
最新的固件版本是 1.0.0.25,如果没有特殊需求,建议刷到这个最新的版本,下载页面在 https://pcsupport.lenovo.com/us/en/downloads/DS506176 ,单独的固件下载链接是 https://download.lenovo.com/pccbbs/mobiles/ar_tbtdockfw10.exe
这个版本的固件在 macOS 下无法调节耳机音量,不过有一个神奇的办法是把其中音频部分的固件单独降级到 1.0.0.12 版本固件里带的 04-0E-80_Rev_0080 就好了
根据其他版本的下载链接推测出来可用的固件下载链接在 https://download.lenovo.com/pccbbs/mobiles/thinkpad_tbt3_dock_web_fw_v1.0.0.12.exe
下载后运行,固件内容会被默认解压到 C:\DRIVERS\ThinkPad_TBT3_Dock_WEB_FW\ 这个目录下,不要在图形界面里刷新,进入 Windows 的命令行,然后用下面这个命令,强制只刷新音频部分的固件
C:\DRIVERS\ThinkPad_TBT3_Dock_WEB_FW\ThinkPad_TBT3_Dock_TVSU_FW.exe /audio /f
最后用 v1.0.0.25 版本固件更新程序的 check 功能看,其他几个模块是最新,音频部分提示目前是 0080 需要升级到 0087 就好了
不过 04-0E-80_Rev_0080 这个音频固件在 Windows 下,会导致扩展坞上的耳机插孔明明插了设备,但 Windows 不认导致无法输出,所以不是接苹果设备的话,还是建议整体都用最新固件