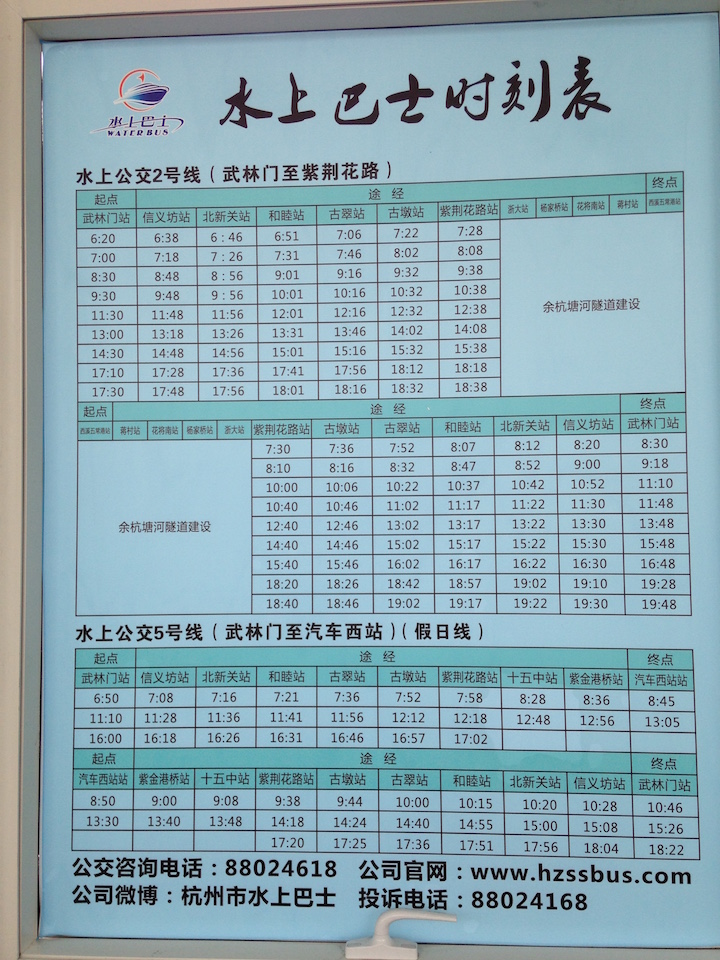
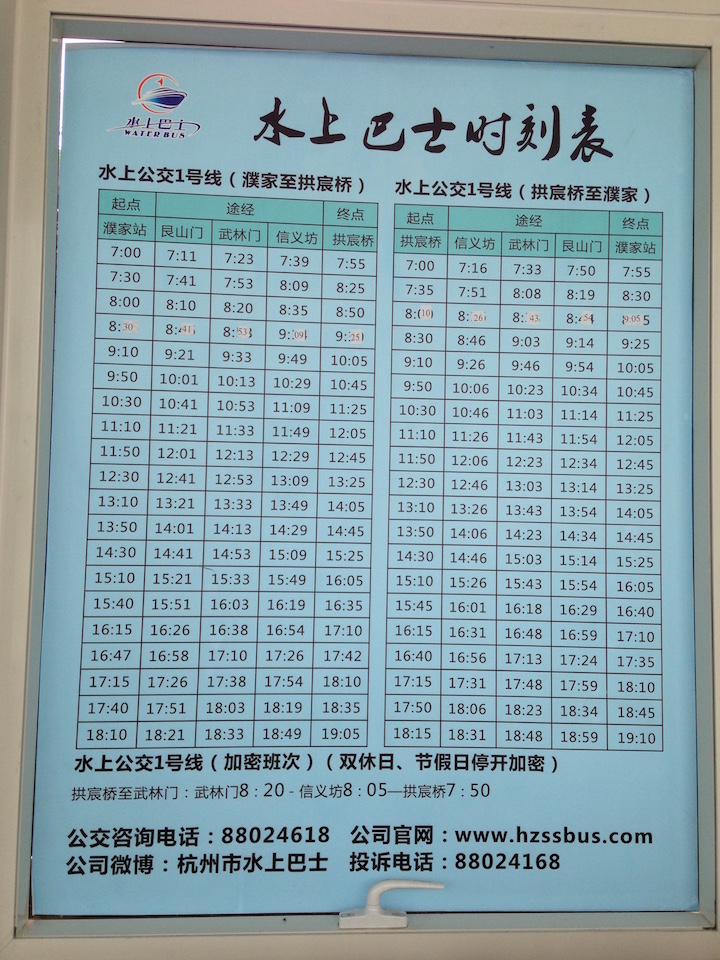
准备
今年过年要在家弄婚礼的事, 要经常来回跑, 家里没车还是不够方便, 去年 Zouyu 就怂恿我过年自驾回去, 不过那时候开车没俩月还不放心, 今年早早规划好我要提前自驾回去看能帮家里准备点啥. 家喵放假晚给她定好火车卧铺后回, 年后到时候看喵的假期情况定是我一个人开回来还是她陪我一起
因为之前没一个人跑过这么长的高速, 家里也各种说不放心, 所以准备工作是做的挺充分的. 路书提前一周左右就开始弄, 全程大部分是高速, 杭州出发走杭新景高速 (S31/33, 也是 G25 长深高速) 往千岛湖方向一直到衢州转沪昆高速 (G60, 浙江省内这段一般叫杭金衢高速, 没有单独编省高速的号), 然后横穿江西过了湖南邵阳转二广高速 (G55), 到永州下高速后就是我的地盘各种自在了
人肉遍历地图把沿途各服务区和主要的交叉口都找出来在地图上标记上, 查了下加油站的情况, 根据以前车油耗经验按 500 公里左右做的加油规划, 提前把两桶油的油卡都准备好, 好像高速服务区基本是被中石化垄断的? 顺带吐槽下目前没找到一个地图产品有在规划高速线路的时候能把服务区限速变道什么的都标出来做路书的功能. 然后人肉算上标记点之间的距离和出发算起的总距离, 大致标上计划到达时间, 以及加油/休息/吃饭的落脚点, 最后地图上密密麻麻是这样的:
回家路书规划
除了图还做了一份表打印出来随车带. 期间发现湖南段从株洲到邵阳 200km 左右的区段居然中间只有一个服务区, 怕到时候在高速上抛锚, 还特意把区间上的几个大出口和换线点也找了出来. 考虑全程大约 1200km 不一定一天能走完, 还特意查了下株洲的酒店以准备分两天跑
回家前几天一远房表哥说要一起回, 他每年都自驾回去好几趟, 这条路熟的很, 刚好路上也能有人轮着开可以尽量压缩休息时间, 换人休息车继续走就是, 这样只要路上不出大问题一天到家妥妥的. 顺带再把途径省份的高速交警微博都关注上, 提前都刷刷看最近路上有没有什么坑爹的点, 手机地图也把离线导航包下好, 再加上总共 3 个 G 的流量我就不信路上会用的掉
回家前一个周末, 找空旷地检查好车况, 机油刹车都没问题, 胎压也补足到满载建议值, 趁油价还没涨去加满油. 提前一天把行李都搬到车上, 一切就绪
2015.2.12, 周四, 腊月廿四, 回家
一早起来洗漱出发, 天还黑着都要开大灯, 到三墩接上表哥表嫂, 七点不到就从三墩上了杭州绕城, 比原计划略早. 从绕城开始就一路畅通, 预计在杭州绕城可能会略堵也没有遇上, 天气也好, 七点四十左右开到桐庐服务区吃早餐换人, 比预计时间早二十分钟以上. 过千岛湖支线没多久, 高速从单向三车道变单向两车道, 问了下表哥说后面都是两车道, 默念这要遇上大车占左道超车那就要被压好一会了

杭新景高速千岛湖方向
过五里枢纽上沪昆后在衢州段遇到意料之中的小堵车, 一路上各种江浙沪闽往西回去过年的车, 做实业的表哥说你看现在经济形式有多不好, 这么早高速上回去过年的人就这么多了, 往年都是要快过年那两天才堵的厉害. 不过还好只是小堵了会, 比预计时间还是早了快半个小时, 浙江段预计偏保守
在衢州服务区换司机的时候看了下前方路段, 江西高速交警在微博上说早上的时候我们这个方向在上饶附近有危化品车在路上出事故, 后方拥堵, 当时估了下我们离那还要一个小时, 看地图上的实时路况也还好能走的动, 只是说前面提前的时间在那一段耗掉就是
过浙赣收费站排队交钱, 过路费 120. 表哥说你怎么不弄个 ETC, 不用排队过去快, 我表示我现在长期趴在杭州城区非核心地段, 一年都难上几次高速, 懒得去办
进江西后发现第一个不太对的是限速从 120 变成 100, 而且看上去是江西全程都 100, 这样的话计划时间估计就要往后拖快一个小时
然后接近上饶事故点还有十几公里就有点要堵车的迹象, 不过看了下地图实时路况, 根据当天在衢州的经历, 估计下高速绕道和在高速上慢慢走耗时也不会差太多, 就在高速上继续前行, 结果走着走着就整个堵死一动不动, 前面车都熄火人都下来在高速上各种吃东西做运动了, 这时已经过了最后一个出口, 就只能在这干耗着. 快两个小时一动不动, 各种吃东西喝水下去活动, 听前面有人说家乡话, 过去搭话说也是一个县的, 他们从温州出发, 凌晨五点多就上高速. 一开始觉得冬天出太阳还挺舒服的, 但是高速上烤的大过年时候居然有二十多度, 中午依然大太阳如果闷车里还要开空调. 等车流慢慢有挪动的迹象时估了下后面的队伍可能有大几十公里了, 随大流慢慢蹭过这十公里又花了快一个小时, 期间停停走走, 还遇到有人油箱盖没盖我们都能慢悠悠的提醒对方接着停住的时候人家再下来盖上

沪昆上饶段遇到事故时被堵死的高速路
过上饶服务区的时候看到罪魁祸首, 一辆应该是装有腐蚀性危化品的车在服务区出口翻了, 地上一层厚石灰在中和, 前面一动不动的时候估计是在事故现场处理封道了, 处理后的事故点只有一条道能通行, 地上石灰有扬尘大家都开的慢, 难怪通了后也还是这么慢慢挪过去的. 热情的上饶人民啊, 就这样被你们挽留了三个多小时
本来还计划在这附近某个服务区进去休整, 结果经过的服务区进去排队都排到高速正线上来, 表哥介绍说这是因为从上海浙江往这边开的车, 到这一段一箱油基本跑完了, 就算排队半个小时也得在这排着等加油. 我们表示不用去方便车上吃喝也够, 看了下油表估计再跑个两百公里都没问题, 还是路过就好. 路上跟表哥扯新能源汽车时恰巧看到一辆比亚迪秦, 反正人家跑在右侧车道, 我们就从左侧慢慢超过去让表哥围观了下这车, 说看起来好像还好的嘛. 江西东边这一段车流也大, 一般开八九十就不错了, 进一步在拖时间
到下午三点经过路书上没找到的龙虎山服务区, 看人比其他地方明显少, 下去休整. 之前中午十二点左右是堵在上饶的路上, 鸡蛋饼什么的已经吃了一圈, 这个点把泡面什么的拿出来也不知道算吃午饭还是下午茶. 弄完准备去加油时看着加油站就不太对, 人少不说车走的速度也很诡异, 开到加油机前面仔细看下原来又是还没启用的状态, 难怪这个服务区之前在地图上都没找到, 原来是新开的
不能加油那等表哥表嫂都吃完就继续往前走, 经过南昌绕城的时候又缓行了一段, 从南昌绕城出来时遇上修路, 路线和之前准备路书时略有不同, 好在提示牌还算清楚. 过了新修的立交枢纽突然开朗起来, 这一段新修的路变成单向四车道, 限速也提到 120, 只是路边的显示屏还按 100 提示 “您已超速”. 过了南昌一点到丰城服务区进去加油, 人不算多, 而且再不加跑下个服务区有点冒险. 这时里程表显示已经跑了快六百四, 油表还有 1/8, 加满油花 218 人民币, 折下来三毛四五一公里, 还是挺省油的
从丰城出来太阳都快落山了, 本来计划顺利的话下午两点能到宜春服务区, 这时候比计划已经落后了快五个小时, 上饶事故是个最大的影响因素, 江西全境限速 100 也是之前没预料的, 衢州和江西东段的缓行加剧了晚点. 经过樟树附近新修的昌樟高速结束, 又变回限速 120 的单向两车道, 而且因为新修路的关系, 樟树枢纽的走法跟之前查的也不一样, 也得亏直行方向还没通, 按路牌正常拐到湖南方向去

过南昌后太阳都快落山了
六点四五十到宜春服务区, 这时天都黑了, 七点多才过赣湘收费站, 过路费 235, 江西高速微博提示的金鱼石 (就是赣湘收费站) 车流量大也没遇到. 车上几个人对这个进度都默默叹气无语, 不过还好后面一路都没再堵车, 而且湖南全境限速是 120, 顺顺当当一路继续, 在株洲附近把收音机打开, 都听到广播里在转湖南台的小年夜晚会, 唉, 无所谓啦, 反正我们家那过的是二十三的小年
在株洲跳马服务区小休, 中午算吃了两顿, 下午在车上有乱七八糟吃了一堆零食, 大家都不饿, 换人后继续前行. 在湘潭附近发现一个新开的服务区, 不是很大, 地图上到现在都查不到, 也算是给 跳马-水府庙-宝庆 这每个区间都 100 公里的坑爹路段多了个休息点. 我们本就没有在这停留的计划, 直接路过
天黑后路上车其实少了挺多, 一是大部分人应该都没有规划开夜车, 二是从江浙沪一代回来过年的只要不是像我们那么靠西也该下高速到家了, 只有在株洲附近因为和好几条南北干线交叉途经的车略多, 后面还在跑的小车, 一半以上都是浙江牌照而不是湖南拍照, 说起来浙江牌的 “浙” 和湖南牌的 “湘”, 隔远点还真不太分的出来
快十一点到邵阳宝庆服务区换人, 再往前没多远就从沪昆转上二广高速, 路上的车一下子就少了好多. 年前二广更多的车流是从广州方向往北去娄底怀化的大巴, 我们就这样看对向的大客一辆接一辆的过, 进永州地界后看对向不知道是有事故还是怎么, 也一动不动排了快有十公里, 这大晚上的被堵的多数还是大巴, 估计上面的人比我们在上饶堵的更是心焦
十二点过一点在永州东下高速, 收费 140, 收费站的妹子虽然说的也是普通话听着也都亲切很多, 交卡时说一句 “一路辛苦了” 在这大半夜的也很暖心
永州城区很多路上都挂起灯笼, 过年的气氛就这么出来了. 把表哥送回家, 我再继续走县道回自己家, 这一路好多年前就修了再没怎么好好大修维护过, 大半夜的乌漆嘛黑啥也看不清, 大灯开到远光也照不到前面多远, 因为稍远点不是急弯就是陡坡, 而且老柏油路年久失修各种坑洞, 一路最多开到四十, 大部分时候是二三十慢慢爬回去
到家时已经凌晨一点多, 比出发前 YY 的七八点能到家吃晚饭晚了五六个小时, 连累爸妈这么晚也没睡等我回去. 把车锁好回家随便洗洗就睡了, 从早上六点起床出发到凌晨一点多到家睡下, 折腾了快二十个小时
2015.3.7, 周六, 正月十七, 返杭
返程没有人能帮忙开车, 家喵负责在车上当吉祥物, 单司机全程 1200KM 本来计划是分两天或三天走, 路上还可以去婺源看个油菜花什么的, 但是年后婚礼搞完去云南玩了一圈, 再回家休息下返回杭州的时间就不太够, 查了下天气路上还可能有大雨, 所以把返程路线定的跟回家时一样, 分两天走, 在上饶左右停下来住一晚
这一路都在开车, 就没有路上照片了, 都是服务区随拍一张报平安的样子
早上七点多吃完早饭从喵家出发, 不用再走小县道, 直接从永州北上高速, 上高速的时候不到八点, 路上车也不算多
从二广拐上沪昆后车又多起来, 九点左右进宝庆服务区休息, 看服务区里也还是一堆浙江牌照的车在年后返程. 邵阳到株洲这段有很长一段路是水泥路, 比沥青路面开起来要颠一点, 回家的时候因为晚上没看清, 而且那段不是我在开车都没注意到
十一点左右到株洲跳马服务区后第二次休息. 走之前特意买了一盒无糖的木糖醇, 一个人开车的话还是需要没事嚼一下保持清醒, 家喵路上不是喜欢睡觉就是发呆, 跟她说话都不怎么理睬, 搞的跟一个人开闷车一样
经过赣湘收费站, 收过路费 143, 此处不管江西还是湖南都叫金鱼石界口. 钱收的是挺奇怪的, 一则居然不是整五块或整十块, 二则这次我比回家时少走了十公里, 过路费反倒还多了三块钱, 不知道怎么算的. 过收费站时排我前面不知道哪里上来的车收了 39, 也不是个整
一点过进到江西宜春服务区, 至此连休息的服务区都跟回家时是一样的. 在宜春服务区看了下有三十块钱的自助餐, 喵过去看了下说没什么好吃的, 然后看上服务区有玉米卖, 就缠着买俩玉米然后去把泡面整上, 理由是你昨天都喊着买泡面现在当然要吃掉啊. 看了下后来微信朋友圈下面的回复, 没吃过高速服务区自助餐的都表示这个价格看起来很实惠的嘛, 吃过的都表示千万不要吃一点也不好吃里面都没肉都是素, 这个, 反正我也没吃过就不发表意见了. 倒是我们坐在餐厅里吃泡面的时候餐厅服务员倒是挺不爽我们不消费又占着个桌, 过来说了两三次, 哎呀你们也没那么多人在吃饭, 我们也坐在靠门的角落里, 不算挡着你们啦, 吃完赶紧走就是了, 谁叫你们服务区除了这其他地方连个桌椅都没呢
吃过饭后明显感觉精力有一些集中度不够, 估计是血液供氧都去消化系统, 上了新的昌樟高速段后更厉害一点, 有一两次都有点恍惚, 赶紧在快三点的时候到丰城服务区, 进去做个长点的休息, 歇一会洗把脸就缓过来. 在这顺便加油, 还是跟过年回家时一样的选择, 不过这次油价从 5.84 涨到了 6.15, 油箱剩的比上次多, 加满花 206
进南昌绕城后发现果然跟高速交警提示的一样车多慢行, 但是刚从 120 限速变到 100 限速现在还一堆车慢悠悠堵着走还真是很不爽, 十来公里又走了快一个小时. 最后发现还是因为施工弄的, 在南昌绕城南线有一个地方上面不知道跨铁路还是跨另一条高速在施工, 下面脚手架搭的只能过一辆车, 地面还坑坑洼洼的大家都悠着点慢慢过, 本来两车道到这变一车道还慢行, 加上应急道上一堆不讲究的从那超过来, 也难怪慢
经过堵点后速度恢复, 这次因为是一个人开车, 路边的提示牌都看的全一点, 发现说沪昆江西东段 (本地叫梨温高速) 本来有维修只是过年停了, 难怪两条车道右边这道明显要坑洼一些, 不超车时老老实实走右边的都觉得要颠的手麻
因为在南昌绕城上堵车耽搁了, 五点半才到鹰潭服务区, 期间淅淅沥沥下了点雨, 不过没下大. 在鹰潭服务区时笨狗看了下还剩下四百公里多点, 都想着要不晚上努把力直接到杭州算了, 家喵不干, 说计划好了要休息的, 而且现在都没吃饭, 最后谈妥说到上饶的时候下高速去城里吃点好的, 当时手机联网不畅, 没找到酒店, 说到上饶下高速再说
鹰潭往东后一堆大车长时间走左侧车道, 不知道是不是修路弄的, 反正一路跑的相对不爽. 快七点时到上饶西出口, 过收费站, 交费 120. 下高速后开始趴路边开手机找酒店, 一开始问了两家都说没停车场, 想着车后座放了一堆乱七八糟的东西虽然不怎么值钱但是万一被人砸窗户也还是挺讨厌的, 还是继续问到一家有停车场的七天. 开过去后也没看到停车场, 在路边趴好后跑去前台问你们停车场怎么走, 前台表示路边划线了的那个就是我们停车场, 你随便找个位子停就好了, 不过我们也不负责的. 当时笨狗就想骂人说路边划线的早停满了好么, 你要不负责你之前说你们有停车场搞个毛线…
附近也没看到什么靠谱的吃的, 再问了两家酒店也都说没停车场或就是路边这种, 亏你们还有脸标自己是四星级? 跟饿着肚子的喵商量说要不我们进市中心那带逛下看看, 找个地方停车先吃点东西然后再找地方住? 看了下状况也没别的选择喵就这么跟着一起往城区走, 坑爹的是手机百度地图导航 GPS 一直找不到信号, 只能拿苹果官方地图 (应该用的是高德) 一路带过去. 在城区晃了一圈死活没找到路边有能合法停车的地方, 酒店也没见到靠谱的, 于是跟喵商量说要不我们往前跑到衢州再说吧, 上饶这地方看着真心不怎么靠谱的样子, 喵饿着肚子表示你说好在这下来怎么又说话不算话, 闹得烦心的狗也很不爽说这地方搞成这样我怎么知道, 我也不想的好么, 出发前查了这边是有旅馆有停车场的, 谁知道他们的停车场是这种路边不管的, 吵起来的两个人都饿着肚子很怨念, 喵表示你就是故意的你是不是还想开回杭州来着, 狗无语上饶这地方就是这样刚才一路过去你也看到了的我有什么办法不过说真的我倒真想过开回杭州最多十一二点就能到家晚上还不用堵车今天也还没下雨
反正看上饶这样也没办法, 浪费一个小时后俩人继续从上饶东上高速, 往前跑到三清山服务区, 在服务区查前面衢州的住宿情况, 问了家离高速不远看起来也还是城区的汉庭, 确定是有自己的停车场还带监控, 电话预定了下就继续过去
经过浙赣收费站 (最后看过路费发票上这个地方江西叫梨园, 浙江叫窑上), 收费 25, 虽然中间省了上饶西到上饶东这一段, 最后收费和年前一路走通是一样的. 在衢州西下高速, 收费 35. 一路顺利的到达酒店, 快到酒店时还接到电话说你们预计什么时候到, 很无奈的说我们刚下高速不过应该马上就到了
在酒店办好入住, 把车停妥到楼后院子里的停车场, 想起闹腾这么久晚上也没正经吃东西, 看马路对面有一堆店还有蛋挞什么的说过去买点蛋挞回来填肚子还可以明天当早餐, 让喵留房间等着狗过去买吃的, 蛋挞店关门了但是有民间版的汉堡店还在营业, 一个鸡肉汉堡加一对鸡翅才十一块钱, 感觉好划算. 路边还看到一堆小吃店, 沙县什么的都有, 默念这么多店明天早餐一定木问题. 累成狗的两只吃过东西冲个脚直接就睡了, 本来还说好可以舒舒服服冲个热水澡好好睡一觉的, 必须再次怨念上饶这个坑爹地, 要不去上饶那绕一个小时, 都不用跟喵俩互相埋怨, 直接到衢州可以淡定的找好酒店去安安稳稳吃饭
第二天早上睡到八点过起来, 看外面开始下大雨, 狗还默默怨念了下早知道还不如昨天直接开回杭州. 去马路对面吃早餐, 这才注意到原来路对面是个什么职业学院, 难怪门口那么多吃的. 在某个疑似煎饼果子的摊后进去要了一笼蒸饺一笼煎饺总共十块, 加一碗豆腐脑一块五, 物价比杭州便宜好多, 喵说要甜豆腐时老板还迟钝反应了一下, 估计这边都吃咸的? 还好没挑起两党纠纷. 坐下吃的时候看清门口一开始以为是煎饼果子的一堆加料的摊是卖盒饭的, 旁边一个大木桶里是米饭, 台上的香肠什么的是添饭里的, 这种吃法之前倒是从未见过
跟在桐庐开厂的前 Google Intern Mentor 汤汤联系上说去参观下他们那, 继续从衢州西上高速, 大雨中奔去桐庐, 一百多公里中间就没休息, 在桐庐的凤川出口下高速, 收费 65. 下去没多远很快就找到汤汤的厂, 规模比我想象的还要大好多, 然后厚颜无耻的从工业园区跑到桐庐城区蹭顿午饭, 感觉桐庐城区还是非常赞的, 绿化什么的也做的非常好, 作为杭州最远的一个县, 房价也最低
吃过饭从桐庐上高速, 汤汤要回杭州滨江, 顺路把我们带到高速入口后走 ETC 先走, 反正高速上也没法跟着走, 就此道别. 一路还是超大的雨, 有电子显示屏提示雨天限速降低, 不过车道变宽到三车道, 一路其他车也没减速, 怕减速后反倒不安全, 还是按平时的限速一路跑到杭州南拐上绕城, 总共不到一百公里也没再中途休息
上绕城的时候两点出头, 开收音机听杭州交通广播, 说绕城西线有事故有部分路段拥堵, 我们也是边走边堵走了三四十分钟才从留下出口出来, 还好没继续往前到三墩, 在留下出口的地方看前面已经完全堵死跟年前回家在上饶遇到的情况一样. 下高速收费 35, 这样算浙江段比年前回去多收了十五的高速费, 虽然在桐庐我们走了大约八公里重复的路, 但是绕城我们也少走了好几公里, 最后看收费细则只能判断是有什么费用是上一次高速就收一次的十块钱, 因为年后这次分三段来跑, 所以多收了
留下进城后也是各种堵, 本来就是周末, 下午回城车流量大, 加上有下大雨, 整个城都堵的够呛, 天目山路这条快速路也车多慢行. 到三点出头挪到古荡加油站, 再次把邮箱加满, 杭州的 92 号油又贵一截, 到 6.30 一升. 然后在城区慢慢挪, 文二路堵不动就从万塘路想拐上文一路, 只可惜哪里都是堵死, 等到小区楼下时已经四点, 搬完一堆箱子, 终于结束旅程
一些经验教训
- 规划高速旅程时, 每两个小时休息一刻钟是必须的, 在不遇上事故和施工堵车的情况下, 限速 120 的线路按 95~100 的旅速规划, 限速 100 的线路按 80~85 来规划才比较靠谱
- 两人轮换的开法可以在压缩在服务区的休息时间, 只要吃饭的时候一起下去呆就好了, 其他时间车进去后人上个厕所出来直接换人就能走
- 加油点需要提前规划好, 高速上大家都都需要加油的服务区 (比如江西境内从上海方向过来一箱油跑完的那几个) 一定会超多人, 一箱油能跑更远很重要, 或者直接就近找出口下高速, 高速出口附近一般都有加油站
- 一个人开车会比较无聊, 有人陪着说话保持大脑清醒很重要, 不能一个人闷闷的开, 或是只听音乐这种没法互动的, 当然也不能旁边那个人一直说要你分神去仔细思考的问题
- 饭后大脑供氧会偏低, 容易犯困, 这时候应该安排个时间间隔不那么长的休息点, 先缓过这阵, 不要硬顶. 另外准备不含糖的木糖醇路上嚼着也能帮忙提神醒脑, 不要买含糖的, 那种嚼完血糖升高会更犯困
- 在不遇上事故或施工堵车的情况下, 一个人开车从杭州到永州一天是可以搞定的, 可能会累点, 但是比在路上陌生城市找落脚的不确定性要靠谱很多, 另外白天城区堵车也严重, 早晚进出城都要明显省时间